

使用wget 缓存api文档到本地
查看一些api文档时,经常会因为网络或权限等原因无法重复在线加载,那么把文档以html的方式缓存到本地,直接用浏览器离线可查看就是好了, 比如nodejs文档, 本文介绍一种使用wget缓存文档的方法。如下
wget \
--recursive \
--no-clobber \
--execute robots=off \
--page-requisites \
--html-extension \
--convert-links \
--restrict-file-names=windows \
--random-wait \
--domains nodejs.org \
--no-parent \
https://nodejs.org/docs/v20.17.0/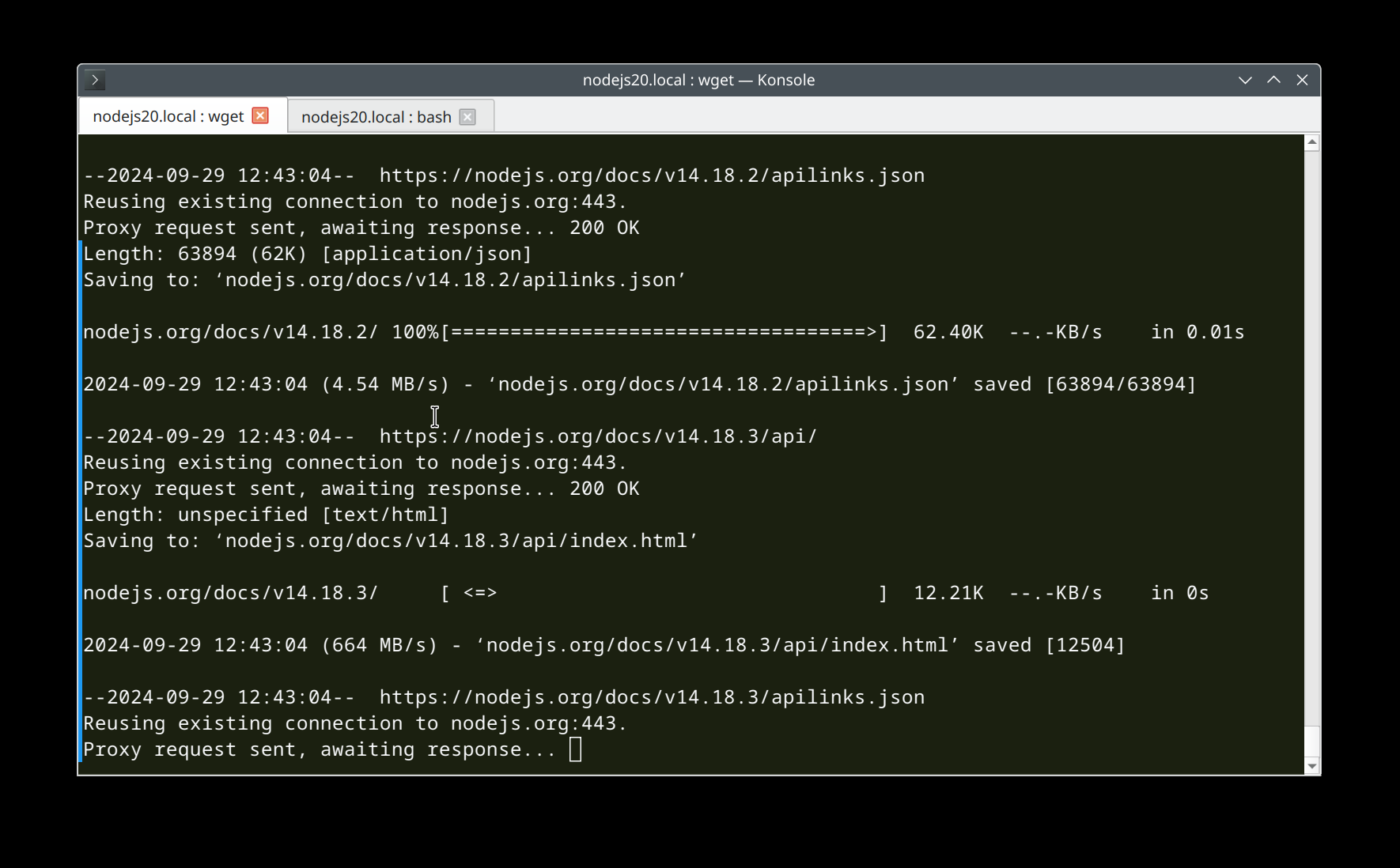
参数解释:
-
--recursive:- 解释:递归下载。
wget会下载指定 URL 及其所有链接的页面。 - 作用:确保下载整个网站或指定目录的内容。
- 解释:递归下载。
-
--no-clobber:- 解释:不覆盖现有文件。如果文件已经存在,
wget不会重新下载它。 - 作用:避免重复下载文件,节省带宽和时间。
- 解释:不覆盖现有文件。如果文件已经存在,
-
--execute robots=off:- 解释:忽略
robots.txt文件。robots.txt通常用于指示哪些页面不应被爬取。 - 作用:允许
wget下载被robots.txt禁止的页面。
- 解释:忽略
-
--page-requisites:- 解释:下载页面所需的所有资源(如图片、样式表、脚本等)。
- 作用:确保下载的页面在离线状态下也能正常显示。
-
--html-extension:- 解释:将所有下载的 HTML 文件保存为
.html扩展名。 - 作用:确保所有 HTML 文件都有正确的扩展名,便于浏览器识别。
- 解释:将所有下载的 HTML 文件保存为
-
--convert-links:- 解释:将下载页面中的链接转换为本地链接。
- 作用:确保下载的页面在离线状态下也能正常导航。
-
--restrict-file-names=windows:- 解释:限制文件名符合 Windows 文件系统的命名规则。
- 作用:确保下载的文件名在 Windows 系统中不会出现非法字符。
-
--random-wait:- 解释:在请求之间随机等待一段时间(0.5 到 1.5 倍的
--wait时间)。 - 作用:避免对服务器造成过大压力,模拟人类访问行为。
- 解释:在请求之间随机等待一段时间(0.5 到 1.5 倍的
-
--domains nodejs.org:- 解释:限制下载的域名仅为
nodejs.org。 - 作用:防止
wget下载其他域名的内容,避免不必要的流量和资源消耗。
- 解释:限制下载的域名仅为
-
--no-parent:- 解释:不访问父目录。
wget不会上升到父目录。 - 作用:确保
wget只下载指定目录及其子目录的内容。
- 解释:不访问父目录。
-
https://nodejs.org/docs/v20.17.0/:- 解释:要下载的初始 URL。
- 作用:指定
wget开始下载的页面。
当然除了wget外,还有更加专业的httrack工具更加简单,这里就不展开了。
特别需要注意的是--execute robots=off参数, 大部分网站会在爬虫文件里指定不允许抓取指定目录,这里强制忽略这个。如果不加的话,会仅仅得到一个index.html文件,其他文件不会被缓存。
下载效果如下:

总结:
这个 wget 命令的目的是递归下载 https://nodejs.org/docs/v20.17.0/ 目录及其所有子目录的内容,同时确保下载的页面在离线状态下也能正常显示和导航。命令还考虑了文件名兼容性、避免重复下载、模拟人类访问行为等因素。